

Ein Team von Forschern aus großen Technologieunternehmen wie Google und Meta hat diesen Montag durch ihr Startup Reka ein neues Sprachmodell vorgestellt, das nach nur einem Jahr Training Ergebnisse zeigt, die mit den Modellen von OpenAI, DeepMind oder Anthropic vergleichbar oder sogar besser sind, laut dem Unternehmen.
Dies geht aus dem Dokument hervor, das die Firma am 15. April veröffentlicht hat, in dem sie die Einführung von Reka Core, ihrem bislang „größten und fähigsten“ multimodalen Modell, ankündigt. Das Produkt der künstlichen Intelligenz strebt danach, sich schnell von Konkurrenten wie ChatGPT zu differenzieren, indem es Interaktivität nicht nur mit Text, sondern auch mit Bildern und Videos bietet.
„Core ist nicht nur ein großes Sprachmodell. Es versteht Bilder, Videos und Audio in einem kontextualisierten Rahmen und ist eine der zwei einzigen umfassenden multimodalen Lösungen, die kommerziell verfügbar sind“, heißt es in dem Text. Das Modell unterstützt 32 Sprachen und eine Kontextfenstergröße von 128.000 Tokens. Es ermöglicht auch die Nutzung von Reka Core über eine API oder auf dem Gerät, um den Einsatz und die Verwendung des Tools zu erleichtern.
Von der Startup-Firma, die 22 Mitarbeiter hat, werden die Vorteile ihres Modells gegenüber den derzeit bekanntesten Lösungen dieser Art hervorgehoben. „Core übertrifft Claude-3 Opus in unserer unabhängigen multimodalen menschlichen Bewertung, übertrifft Gemini Ultra in Videoaufgaben, was angesichts unseres multimodalen Ansatzes ein Schlüsselfokus ist, und ist vergleichbar mit GPT-4V in MMMU. In Sprachaufgaben ist Core wettbewerbsfähig mit anderen führenden Modellen bei gut etablierten Benchmarks“, so die Firma.
Zu den weiteren Stärken des Modells gehören laut den Schöpfern seine Fähigkeiten in anspruchsvoller mathematischer Argumentation und seine Fertigkeit im Codieren.
Dani Yogatama, Mitbegründer und CEO von Reka, erklärte gegenüber den Medien, dass der einzige KI-Dienst, der dieselben Funktionen wie Core bietet, Gemini Ultra von Google ist. Yogatama wies auch darauf hin, dass es derzeit keine Pläne gibt, das Modell als Open-Source zu veröffentlichen, da ein Gleichgewicht angestrebt wird, das die Lebensfähigkeit des Geschäfts sichert.
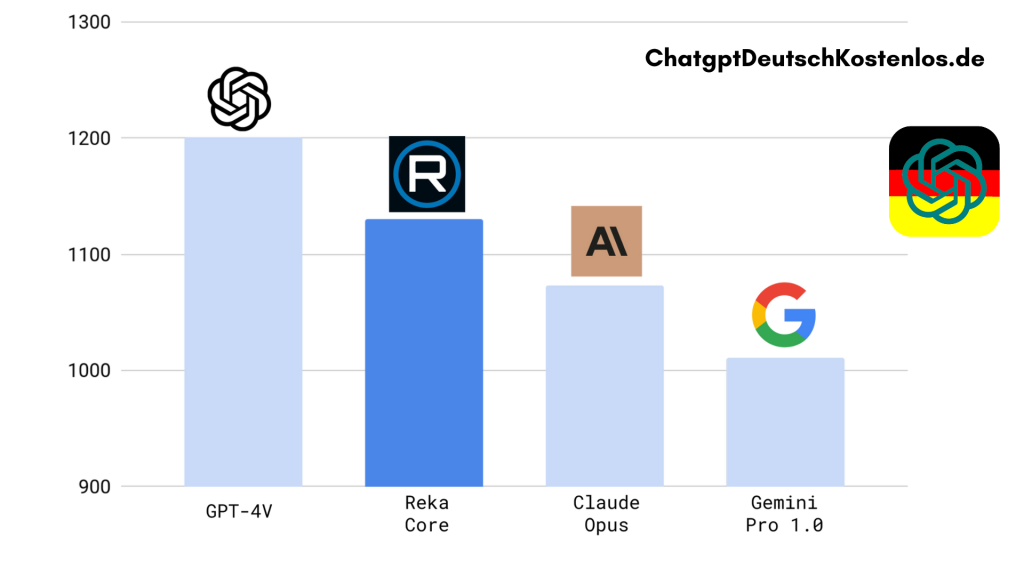
Reka Core, das neue KI-Modell, das Videos analysieren kann und ChatGPT die Stirn bietet
Was die Kosten für die Nutzung ihres Modells angeht, so gibt das Dokument an, dass „der Preis für unseren API-Start bei 10$ pro Million Eingabe-Tokens und 25$ pro Million Ausgabe-Tokens liegt“. Das Unternehmen betrachtet diese Gebühr als „wettbewerbsfähig“ im Vergleich zu konkurrierenden Anwendungen, wenn man die Leistung berücksichtigt.
Fähigkeiten für Video, Bild und Audio
Der Hauptunterschied zwischen großen Sprachmodellen (LLM) wie ChatGPT und großen multimodalen Modellen (LMM) wie dem von Reka vorgestellten besteht darin, dass letztere die Fähigkeit haben, Eingaben in mehreren Formaten neben Text zu verarbeiten, wie Video-, Bild- und Audiodateien. Mit dieser Technologie positioniert sich das Startup an der Spitze der Unternehmen seiner Branche.
Um die Öffentlichkeit über die Anwendungen von Reka Core zu informieren, hat das Unternehmen ein Video auf X veröffentlicht, in dem seine KI den Trailer der Netflix-Serie „Das Problem der drei Körper“ analysiert. Wie im Clip zu sehen ist, kann Core Schauspieler identifizieren, Szenen beschreiben oder sogar ein Python-Skript schreiben, in dem das mathematische Problem, auf das sich die Serie bezieht, visualisiert wird.
Die Firma arbeitet bereits mit den Unternehmen Snowflake und Oracle sowie der Organisation AI Singapore zusammen. Neben der Ankündigung hat das Startup auch ein weiteres Dokument auf diesem Link geteilt, in dem Training, Daten und Strukturen der Reka-Modelle detailliert beschrieben werden. Das Modell selbst kann von ihrer Login-Seite aus getestet werden.
Zu den Mitarbeitern von Reka gehört ein Spanier, der baskische Mathematiker und Ingenieur Aitor Ormazabal, der eine Position im technischen Team innehat.






No Responses